最近因为新型冠状病毒SARI的关系,只能窝家里了哈,太无聊了,就打算去学习下python哈,还成功接了一小单哈。案例实录点下面的链接查看:
<p style="font-size:24px;font-weight:400;color:#333333;font-family:" text-align:center;background-color:#ffffff;"="">python合并excel导入sql server 2008的大坑记录
回来说说这个项目,其实很简单,就是给一个docx的word文件添加一个图片进去,我还是看了官网的例子写的代码。官网的例子在这里https://python-docx.readthedocs.io/en/latest/
1.jpg这个图片是通过reques.get获得的百度文库的一个图片,下面这段是为了测试简单些的,主要的功能是需要实现百度文库下载word的一个功能,并将图片插入到word的具体位置里面。
import re
import os
from docx import Document
from docx.shared import Inches
import docx.image
document = Document()
img='1.jpg'
document.add_picture(img)
document.save('2.docx')执行报错了,有点小崩溃了哈。
Traceback (most recent call last):
File "split.py", line 23, in
document.add_picture(img)
File "C:\Users\wenli\AppData\Local\Programs\Python\Python37\lib\site-packages\docx\document.py", line 72, in add_picture
return run.add_picture(image_path_or_stream, width, height)
File "C:\Users\wenli\AppData\Local\Programs\Python\Python37\lib\site-packages\docx\text\run.py", line 62, in add_picture
inline = self.part.new_pic_inline(image_path_or_stream, width, height)
File "C:\Users\wenli\AppData\Local\Programs\Python\Python37\lib\site-packages\docx\parts\story.py", line 56, in new_pic_inline
rId, image = self.get_or_add_image(image_descriptor)
File "C:\Users\wenli\AppData\Local\Programs\Python\Python37\lib\site-packages\docx\parts\story.py", line 29, in get_or_add_image
image_part = self._package.get_or_add_image_part(image_descriptor)
File "C:\Users\wenli\AppData\Local\Programs\Python\Python37\lib\site-packages\docx\package.py", line 31, in get_or_add_image_part
return self.image_parts.get_or_add_image_part(image_descriptor)
File "C:\Users\wenli\AppData\Local\Programs\Python\Python37\lib\site-packages\docx\package.py", line 74, in get_or_add_image_part
image = Image.from_file(image_descriptor)
File "C:\Users\wenli\AppData\Local\Programs\Python\Python37\lib\site-packages\docx\image\image.py", line 55, in from_file
return cls._from_stream(stream, blob, filename)
File "C:\Users\wenli\AppData\Local\Programs\Python\Python37\lib\site-packages\docx\image\image.py", line 176, in _from_stream
image_header = _ImageHeaderFactory(stream)
File "C:\Users\wenli\AppData\Local\Programs\Python\Python37\lib\site-packages\docx\image\image.py", line 199, in _ImageHeaderFactory
raise UnrecognizedImageError
docx.image.exceptions.UnrecognizedImageError
网上搜了半天也没有答案哈,多半是把try,然后export docx.image.exceptions.UnrecognizedImageError as e: pass,直接忽略这个异常报错,然后继续执行代码,查看了下生成的docx文件,发现还是没有把图片插入进来,解决不了目前的问题。
然后就怀疑是图片格式的问题,然后将图片用电脑的修图软件另存为png格式,发现测试ok了哈。欣喜若狂,修改了下下载request.get的代码,将其保存为png的图片,结果还是报一样的错,还以为是reqeust下载图片不行,换了urllib也是一样,头大了哈。
解决方案:
首先千万不要去质疑python大师写的模块有问题哈,反而走了不少弯路,站长之前是写PHP的,之前做过一个最坑的项目就是用phpexcel读取excel文件,不知道是微软的锅还是phpexcel的锅,兼容性真的不是很好呀,所以带着这种思维,很容易的就觉得人家写的代码有问题哈,其实自己还是个小白哈。
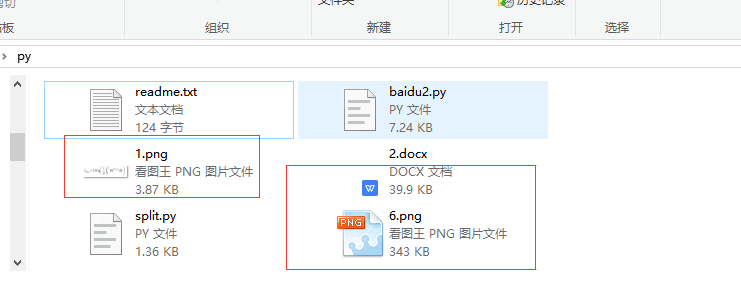
最后发现是下载图片的时候出了问题,导致无法插入,正常状态下文件夹下可以显示图片缩略图1.png,但是之前写的py下载图片的程序下载过来的,只能显示图标6.png,不能显示具体的图片内容。好了就分享到这里,py真是个好东西哈,要学习编程的捷径就是去看别人的项目,搭建别人的项目,看看别人怎么写的代码,然后去理解,去修改。

热门文章
python-docx给docx的word添加JPG图片报错docx.image.exceptions.UnrecognizedImageError,最终有问题的还是自己的代码,python-docx写的真是不错,一定要注意自己生成的代码跟图片有没有问题。
要真正把宝塔的python项目管理器使用起来,需要经历一番复杂的操作才可以,否则这个东西就是个鸡肋。
python在批量处理excel跟批量导入信息到数据库都是最优选择,兼容到xp了,没话说,老的项目一样能搞定。打包完提示不是有效的win32应用程序都是小问题了。
使用pony orm写的数据库底层,如何调试并打印执行的sql语句是否有问题,看这里就够了。
没有免费合适的批量压缩图片的工具,我们就用python造一个吧。
python批量上传工具,终于不用担心数据量太大网页上传会超时的问题了。
PYTHON3腾讯云阿里云宝塔文件夹一键打包FTP上传工具,为了偷懒,把VUE打包、FTP批量上传文件的工作交给PYTHON来完成,直接双击然后就可以忙别的活了。